


Knowledge Management
The traditional view of knowledge management has treated knowledge in terms of prepackaged or taken-for-granted interpretations of information. However, this static and contextual knowledge works against the generation of multiple and contradictory viewpoints that are necessary for meeting the challenge posed by wicked environments. - Dr. Yogesh Malhotra in Toward a Knowledge Ecology for Organizational White-Waters
Data is organized into information by combining it with prior knowledge and the person's self-system to create a knowledge or mental representation (Marzano, 1998). This is normally done to solve a problem or make sense of a phenomenon.
This knowledge representation is consistently changing as we receive new inputs, such as new learnings, feelings, and experiences. This causes the knowledge representation to change due to our brains being branched or interconnected to other representations, rather than layered.
Since our brains are branched, knowledge is dynamic, that is, our various knowledge representations change and grow with each new experience and learning.
Due to the complexity of knowledge representations, they not easily captured by documents, rather they reside within the creator of the representation. In many cases, the knowledge representation stays within the creator, in which case the “flow of knowledge” stops.
A Knowledge Management (KM) system, which may be as simple as a story or as complex as a million-dollar computer program, attempts to capture a snapshot of the person's knowledge representation. This is called knowledge harvesting. In the case of a story, the knowledge representation is passed onto others by means of a verbal snapshot. In the case of a computer program, it resides in a database that may be utilized by others. It is only a “snapshot” as further experiences and learnings within the creator may change the knowledge representation, while the static snapshot remains the same. In addition, it is only a partial snapshot as the full context of the original knowledge source is almost never fully captured.
Others may make use of the knowledge representation snapshot by using the story or tapping into the KM system and then combining it with their prior knowledge. This in turn forms a new or modified knowledge representation. This knowledge representation is then applied to solve a personal or business need, or explain a phenomenon.
Depending upon the KM system and the novelty of the situation, a snapshot of this new knowledge representation may or may not be entered into the system.
Knowledge Management Comes Quite Naturally to Humans
While there are normally only five ways to organize information—LATCH (Location, Alphabet, Time, Category, or Hierarchy), these five ways have a lot of versatility (Wurman, 2001). For example, a youngster with a toy car collection may sort them by color, make, type, size, type of play, or a dozen other divisions. The youngster can even make up categories as new divisions, play activities, or wants appear. However, a computer is considered "intelligent" if it can sort a collection into one category. Yet, many organizations are placing their bets on computer systems due to the amount of data such systems can hold and the speed at which it can sort and distribute once such categories and data are made known to it.
Knowledge Management Framework

Knowledge Acquisition
This is the gathering of knowledge. Do not try to gather every bit of knowledge throughout your organization... there is way too much! Find one or two good sources to work from. For example, Executive Edge (Dec 00/Jan 01) reported that Hill & Knowlton, a New York based public relations firm, that has offices and clients scattered across the globe, found that an enormous amount of its knowledge was tied up in emails. So, it implemented a system that allows strategically important email to be saved in a data repository that can be called upon by others when needed.
Knowledge Storage and Organization
This is where the knowledge will be stored. Much of it today is stored in paper based documents, such as books and manuals. However, this makes it hard to update and distribute. Paper based storage systems also lack dynamic storage systems. For example, a youngster's toy car collection can be categorized in a number of ways to suit his or her needs, while a manual is generally organized by chapters and key words . Moore's Law holds that the maximum processing power of a microchip at a given price doubles roughly every 18 months. In other words, computers become faster, but the price of a given level of computing power halves, which gives computers their organizing power.
Knowledge Distribution
A mechanism, such as an Intranet or Internet, allows the data in the repository to be quickly disseminated throughout an organization. Bob Metcalfe, the inventor of Ethernet technology (the enabler that allowed the information genie to jump out of the bottle), has a law named after him—Metcalfe's Law: the asset value of a computer network increases exponentially as each new node (individual user) is added to it. This is because each new user brings along a wealth of new linkages and resources, so the total network value grows far richer than the mere sum of its parts. This is what gives the Internet its power. Gilder's Law: the total bandwidth of communication systems will triple every 12 months, describes a decline in the unit cost of the net, which in turn allows more information to be distributed over the net.
Knowledge Application
This is the actual use of the knowledge and is generally measured by its effectiveness and usefulness. Thus, if you have bad information going in, you will have bad information coming out. Note: in most instances, the users and the knowledge drivers are the one and the same, that is, the users not only withdraw the information, but they must also input information. To insure that good information goes in, involve the users from day one in the planning, design, and building of the system. It needs to mimic the way the users perform their tasks; not the way you perform your tasks. If they find it clumsy and hard to use, they will not use it. Build it by using metaphors from their working environment, not by using buzzwords from your environment.
Extracting Knowledge
Jeffery Pfeffer and Robert Sutton (2000) write that companies have wasted hundreds of millions on worthless knowledge management systems:
- The most valuable employees often have the greatest disdain for knowledge management. Curators badger these employees to enter what they know into the system, even though few people will ever use the information.
- The managers of these systems know a lot about technology, but little about how people actually use knowledge on the job.
- Tacit knowledge is extremely difficult to capture into these systems, yet it is more critical to task performance than explicit knowledge.
- Knowledge is of little use unless it is turned into products, services, innovations, or process improvements.
- Knowledge management systems work best when the people who generate the knowledge, are the same people who store it, explain it to others, and coach them as they try to implement it. These systems must be managed by the people who are implementing what is known, not those who understand information technology.
For a knowledge management strategy, see Capturing Lessons Learned with an AAR.
Next Step
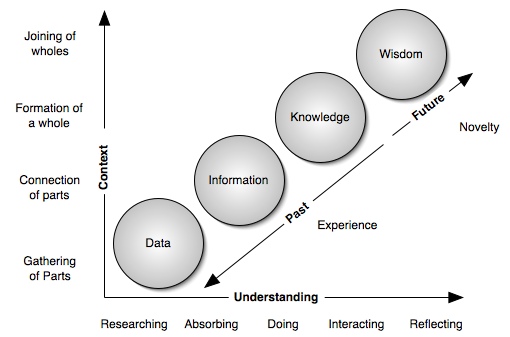
Click on the various parts of the chart to learn more about that topic
Reference
Marzano, R. J. (1998). A Theory-Based Meta-Analysis of Research on Instruction. Aurora, Colorado: Regional Educational Laboratory. Retrieved May 2, 2000 from http://www.mcrel.org/pdf/instruction/5982rr_instructionmeta_analysis.pdf
Pfeffer, J., Sutton, R. (2000). The Knowing—Doing Gap: How Smart Companies Turn Knowledge into Action. Cambridge, MA: Harvard Business School Press
Wurman, S. (2001). Information Anxiety 2. Indianapolis: Que.